
boltdb介绍
boltdb是一个轻量级的、嵌入式的golang原生key-value DB,在etcd中作为存储后端使用。它使用了b+树、mmap、copy on write等技术,支持读写事物。本文将结合技术原理和内部实现来分析boltdb。
boltdb的官方介绍如下:
Bolt is a pure Go key/value store inspired by Howard Chu’s LMDB project. The goal of the project is to provide a simple, fast, and reliable database for projects that don’t require a full database server such as Postgres or MySQL.
boltdb使用了b+树来持久化数据,使用了mmap来方便数据的读取,而写入并没有直接使用mmap,而是采用了写文件的方式来写入数据。
至于为什么不直接采用mmap来写数据,LMDB中给出了如下原因,是一种基于数据完整性的考虑:
The memory map can be used as a read-only or read-write map. It is read-only by default as this provides total immunity to corruption. Using read-write mode offers much higher write performance, but adds the possibility for stray application writes thru pointers to silently corrupt the database. Of course if your application code is known to be bug-free (…) then this is not an issue.
boltdb中的b+树
boltdb底层使用了b+树这种数据结构来持久化kv数据。
节点类型
基础的b+树有两种节点,即叶子节点和内部节点,内部节点不存储数据,只存用来定位数据的key。boltdb中的叶子节点,其实并非真正意义上的叶子节点,因为它还可以有子节点,这主要是为了建模sub bucket。
page
boltdb以page为单位来使用、管理底层的存储,每个page就是b+树的一个节点。
page的大小默认等于操作系统内存page的大小:
// default page size for db is set to the OS page size.
var defaultPageSize = os.Getpagesize()
page header
所有不同类型的page,都有相同的page header,如下。id表示page的id;flags用来标记page的类型等;count记录了该page存储了多少数据(如键值对);overflow表示,page中存储的元素比较大,有可能需要跨越多个连续的page才存储的下,overflow的大小就表示额外的连续的page数目。ptr则指向header之后,数据存储区域的起始地址。
type page struct {
id pgid // page id
flags uint16 // page type flag
count uint16 // count for stored key-value pairs
overflow uint32 // whether this is a huge page with more consecutive pages
ptr uintptr // start of data region
}
page data
page的数据区域,根据不同的page类型,会存储完全不同的数据。
meta page
为了维护整个db的状态,boltdb中定义了meta page,如下。根据其定义可以看出,meta page存有root bucket的元信息,比如root bucket存在哪一个page中;freelist则指向了存储所有可用的page的id的page;txid则保存了这个meta page对应的写事务的事务id;checksum是对meta page做的checksum,用来验证meta page是否损坏。
type meta struct {
magic uint32
version uint32
pageSize uint32
flags uint32
root bucket
freelist pgid
pgid pgid
txid txid
checksum uint64
}
// bucket represents the on-file representation of a bucket.
// This is stored as the "value" of a bucket key. If the bucket is small enough,
// then its root page can be stored inline in the "value", after the bucket
// header. In the case of inline buckets, the "root" will be 0.
type bucket struct {
root pgid // page id of the bucket's root-level page
sequence uint64 // monotonically incrementing, used by NextSequence()
}
leaf page
b+树中,只有叶子节点才会存储key-value数据,而内部节点,只会存储用来定位的key信息。leaf page从数据区开始,首先存储的是key-value pair的元信息,比如,key、value的大小,key-value pair在数据区中的相对位置等。在pos指定的地方,则存储了真实的key和value。
// leafPageElement represents a node on a leaf page.
type leafPageElement struct {
flags uint32
pos uint32
ksize uint32
vsize uint32
}
branch page
branch page和leaf page相似,不同之处在于,它不存储value,只存储用来定位的key,和对应的存储数据的page的page id。
// branchPageElement represents a node on a branch page.
type branchPageElement struct {
pos uint32
ksize uint32
pgid pgid
}
freelist page
freelist page会存储所有可用的page的page id,它并不会参与b+树的调整。它存储数据的格式也很简单,有一个简单的点需要注意,从page header的定义中,我们可以发现,page header最多只能记录64K(uint16)个数据,对于freelist来说,这很可能不够用。freelist的做法是,如果发现需要记录的free page超过64K,则设置freelist_page.count = 0xFFFF,然后使用数据区的第一个uint64大小的空间来存储free page的数量,接下来再存储所有的page id。
boltdb中的bucket
boltdb中定义了bucket的概念,所有kv数据必须存储在一个bucket中。bucket可以嵌套。bucket元数据也是作为一个key-value pair,存在某一个page中,具体格式如下:
// bucket represents the on-file representation of a bucket.
// This is stored as the "value" of a bucket key. If the bucket is small enough,
// then its root page can be stored inline in the "value", after the bucket
// header. In the case of inline buckets, the "root" will be 0.
type bucket struct {
root pgid // page id of the bucket's root-level page
sequence uint64 // monotonically incrementing, used by NextSequence()
}
inline bucket
boltdb支持inline bucket。inline bucket的意思是指,把某个sub bucket的所有数据,以落盘的格式(page header,data region),作为value,直接存在parent bucket中。当然,inline是有条件的,就是这个sub bucket的大小不能超过pageSize/4。
// Returns the maximum total size of a bucket to make it a candidate for inlining.
func (b *Bucket) maxInlineBucketSize() int {
return b.tx.db.pageSize / 4
}
root bucket是b+树的根节点,一切key-value pair、子bucket,都必须从root开始查找。每次创建一个新的Tx(事务)时,tx都会调整自己的root bucket,来指向meta page存的root bucket。
boltdb的disk layout
首次打开的空数据库
对于第一次打开的数据库空文件,bolt会对其做初始化,填充好两个meta page,一个空的freelist,和一个空的root page。可以使用bolt来校验一下前4个page,发现两个meta page存储的内容基本相同,除了txn ID;freelist指向page 2,root page则指向3,当前一共有4个page。
~/go/src/g/j/bolt_debug bolt page db 0
Page ID: 0
Page Type: meta
Total Size: 4096 bytes
Version: 2
Page Size: 4096 bytes
Flags: 00000000
Root: <pgid=3>
Freelist: <pgid=2>
HWM: <pgid=4>
Txn ID: 0
Checksum: 07516e114689fdee
~/go/src/g/j/bolt_debug bolt page db 1
Page ID: 1
Page Type: meta
Total Size: 4096 bytes
Version: 2
Page Size: 4096 bytes
Flags: 00000000
Root: <pgid=3>
Freelist: <pgid=2>
HWM: <pgid=4>
Txn ID: 1
Checksum: 264c351a5179480f
~/go/src/g/j/bolt_debug bolt page db 2
Page ID: 2
Page Type: freelist
Total Size: 4096 bytes
Item Count: 0
Overflow: 0
~/go/src/g/j/bolt_debug bolt page db 3
Page ID: 3
Page Type: leaf
Total Size: 4096 bytes
Item Count: 0
执行过多次读、写事务后的数据库layout
在做了一些创建bucket、sub bucket,插入key-value pair之后,meta page记录如下,可以看出有新的page被使用了,并且root page和freelist page都发生了变化。
~/go/src/g/j/bolt_debug bolt page db 0
Page ID: 0
Page Type: meta
Total Size: 4096 bytes
Version: 2
Page Size: 4096 bytes
Flags: 00000000
Root: <pgid=6>
Freelist: <pgid=7>
HWM: <pgid=8>
Txn ID: 2
Checksum: 6d38b867d6b9b7e0
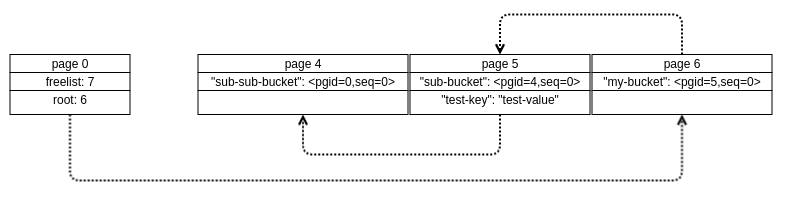
从root page开始追踪,可以得到当前的b+树结构,如下图。使用bolt工具来查看这写page的类型,发现page 0是meta page,4、5、6都是leaf page。这种leaf page仍然包含孩子节点的做法,主要是为了建模nested bucket。
boltdb的事务
boltdb支持两种事务:读写(可写)事务和只读事务。
读写事务
通过调用db.Begin(true),或者db.Update(…),我们可以创建一个读写事务。顾名思义,读写事务可以对db中的数据进行修改。一个读写事务同样会修改meta page(至少会修改其txn id,并会重新commit freelist)。boltdb使用了COW技术,即被修改了的page会被写到一个新的page,而不是进行原地修改,未修改的page则不动。被修改了的page,称之为dirty page。一个事务会记录在这个事务过程中创建的所有的脏页。通过COW和脏页的记录,则很好实现事务的提交和回滚。
在一个读写事务中,不单单会产生新的脏页,也会有旧的页需要被释放。为了方便事务的回滚,在本次事务中被释放掉的页,并不会立即释放,而是会被标记为pending状态。只有当本次事务提交之后,bolt内部才会尝试释放这些pending的page。这里也可以看出,本次事务无论commit还是rollback,都不会破坏上一个已完成的事务的数据。
读写事务中,Put操作会往合适的位置添加key-value pair,而Delete则会删除指定的key-value pair,这些操作会导致b+树不再满足其性质,或者某些bolt内部的性质被破坏。于是,在提交一个读写事务的时候,bolt内部会触发对b+树的调整,首先做rebalance来尝试合并节点,再做spill操作来尝试分裂某些节点。
在Commit过程中,数据的落盘顺序也很重要。bolt首先对脏页进行了落盘,其中也包括了新的存储freelist的页。所有脏页写完后,会调用一次fdatasync来确保数据正确的写入了磁盘,以防止机器断电导致数据还没有从page cache真正写到disk上。然后在最后一步,才是将修改过得meta page落盘。
如果meta page并没有写完而机器断电了怎么办?为了防止这种情况导致db损坏,meta page中还存储了一个用来做数据校验的hash值,每次打开db时,都会对读入的meta page的数据重新计算一次hash,并且和读入的hash做比较看数据是否损坏,如果这个meta page损坏了,就说明最近的这次事务并没有正确完成,则回滚到上一个完成的事务的状态(从另一个txn id小1的meta page中读取元数据)。
只读事务
只读事务不会修改db中的数据,尝试在一个只读事务中进行修改操作,都会返回错误。只读事务之间不会互斥,同时也不会和读写事务互斥,也就是说,我们可以在任何时间打开一个只读的事务。需要注意的是,bolt内部需要记录只读事务和page的对应关系,因为需要保证某个只读事务本该能够访问到的数据不会在只读事务还没结束的时候就被释放掉。
bolt中,创建一个只读事务,其实并不会增加其txn id,所以,一个只读事务相当于是指向了当前最近一次完成的读写事务的状态,或者说,指向了db在这个只读事务打开的那个时间点的一个snapshot。bolt内部记录了只读事务和page的映射关系,从而保证了这个时间点后的读写事务并不会修改这个snapshot占用的page(直到这个只读事务结束后,这个page才有机会被释放)。以下代码片段可以辅助我们来理解如何保证这个snapshot的数据不会被意外释放。
首先,在创建一个只读事务的时候,db中会将这个事务记录起来,即存在db.txs中。
func (db *DB) beginTx() (*Tx, error) {
// ...
// Keep track of transaction until it closes.
db.txs = append(db.txs, t)
n := len(db.txs)
// ...
}
释放pending的page这个操作,实际上是在创建一个读写事务的时候来触发的。可以看到,这个函数会尝试释放所有除了当前只读事务(db.txs)之外的其他事务中的pending page(待释放的页)。
// freePages releases any pages associated with closed read-only transactions.
func (db *DB) freePages() {
// Free all pending pages prior to earliest open transaction.
sort.Sort(txsById(db.txs))
minid := txid(0xFFFFFFFFFFFFFFFF)
if len(db.txs) > 0 {
minid = db.txs[0].meta.txid
}
if minid > 0 {
db.freelist.release(minid - 1)
}
// Release unused txid extents.
for _, t := range db.txs {
db.freelist.releaseRange(minid, t.meta.txid-1)
minid = t.meta.txid + 1
}
db.freelist.releaseRange(minid, txid(0xFFFFFFFFFFFFFFFF))
// Any page both allocated and freed in an extent is safe to release.
}
继续看releaseRange这个函数,看看freelist究竟是如何释放page的。如注释所说,这个函数会把所有在[begin,end]这个事务区间内分配的又被标记为pending的page释放掉。再看一下这个函数被调用的时候传入的参数,可以发现,freePages并不会释放当前只读事务引用到的但是之后被标记为pending的page,这就保证了只读事务内可以读到那个时间点上有效的数据。
// releaseRange moves pending pages allocated within an extent [begin,end] to the free list.
func (f *freelist) releaseRange(begin, end txid) {
if begin > end {
return
}
var m pgids
for tid, txp := range f.pending {
if tid < begin || tid > end {
continue
}
// Don't recompute freed pages if ranges haven't updated.
if txp.lastReleaseBegin == begin {
continue
}
for i := 0; i < len(txp.ids); i++ {
if atx := txp.alloctx[i]; atx < begin || atx > end {
continue
}
m = append(m, txp.ids[i])
txp.ids[i] = txp.ids[len(txp.ids)-1]
txp.ids = txp.ids[:len(txp.ids)-1]
txp.alloctx[i] = txp.alloctx[len(txp.alloctx)-1]
txp.alloctx = txp.alloctx[:len(txp.alloctx)-1]
i--
}
txp.lastReleaseBegin = begin
if len(txp.ids) == 0 {
delete(f.pending, tid)
}
}
sort.Sort(m)
f.ids = pgids(f.ids).merge(m)
}
boltdb中的迭代器 - cursor
boltdb中存储的数据,是按照key来排序的。那么在插入、和查找数据的时候,就需要能够快速定位到正确的page。bolt实现了cursor这个迭代器,来辅助插入、删除等操作。
总结
boltdb以较小的代码规模,使用mmap、COW等技术,以b+树作为核心数据结构,实现了一个小巧的、支持事务的key-value数据库,可以作为实现更为复杂的系统的基石。