
Incremental backup based on rsync algorithm
Recently, I have to build a disaster recovery service to backup and restore critical data in our productions. Simply speaking, this service needs to:
- do file based backup for specific directory
- support multi-version
- support incremental backup
- save backups in remote storage system
- support restoration of specified version
Disaster recovery is a large topic. Here in this post, I will mainly focus on the implementation of incremental backup.
So, what is incremental backup? To figure out incremental backup, let’s review different backup types first.
Backup types
The most common backup types are full backup, differential backup and incremental backup.
Full backup
This type of backup makes a copy of all data to another set of media. The advantage is that it requires a minimal time to restore data. However, the disadvantages are that it takes longer to perform a full backup than other types, and it requires more storage space.
Differential backup
These backups start with a full backup to store all files. Then, differential backups are run that store only the data that has changed since the last full backup. This saves much of the storage space, time and resources that would be needed to just do continual full backups.
Incremental backup
An incremental backup includes only the data which has changed since any previous backup. Incremental backups require the least amount of storage space, but because they must be run separately during a recovery they can take more time to retrieve data.
There can be 2 types of incremental backup according to how we maintain full backup in a backup chain. The forward incremental backup method produces a backup chain that consists of the first full backup and a set of forward incremental backups following it. The reverse incremental backup method produces a backup chain that consists of the last full backup and a set of reverse incremental backups preceding it. These two different methods lead to different backup and restore efficiency.
Which backup type to choose
In our scenario, we do backup periodically while we restore only when we have to, so backup efficiency is more important to us. Hence, the forward incremental backup method is adopted.
Delta generation
Backup programs need to deal with large volumes of changing data. In the incremental backup, only delta is stored to save space.
There are a few remote delta generation algorithms can be used. They operate on chunks of data from files and only upload new chunks. Some of them operate on variable length chunks. Restic, for example, uses Content Defined Chunking (CDC) algorithm to generate variable length chunks and detect duplications. While some of them operate on fixed-length chunks. Duplicity uses rsync algorithm working on fixed-length chunks to generate signatures of files.
Currently, rsync algorithm is implemented in golang as a standalone library (the whole service is developed in golang). The reason why re-inventing the wheel is that:
- rsync tool is not enough to model incremental backup
- have to call cpp librsync thru cgo while memory manipulation in cgo is hard to control
- existing golang rsync libraries are not well tested
Some implementation details of this library can be found in another post.
Incremental backup based on rsync algorithm
Elements in rsync algorithm
In rsync algorithm, a signature of a file contains weak rolling hash and strong hash value computed for each fixed-length chunks of this file. A delta file contains the reference to existing chunks and new chunks which could be in variable length. As below figure shows, the delta file contains the start position and chunk length of existing chunks in original file, and new chunks in the new file.
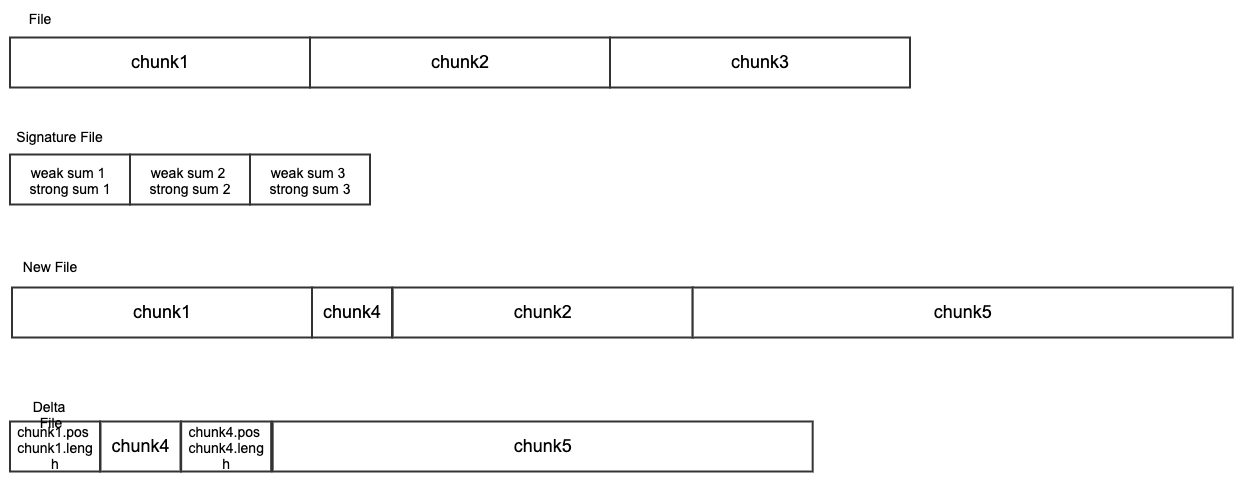
Generate incremental backup for a file
These elements are enough for us to model incremental backup. For example, to back up the file named File at time t0, a full copy (Delta at t0 is same as File at t0) and its signature are generated and saved. At time t1, the Delta at t1 is generated by File at t1 and Signature at t0, the Signature at t1 is calculated at the same time, these two files are saved, File at t1 is dropped. At time t2, this process is repeated to generate Delta at t2 and signature at t2.
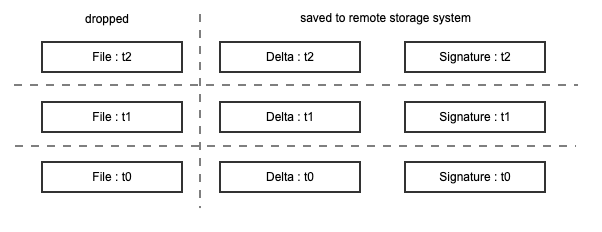
Restore specific backup for a file
To restore File at t2, for example, Delta at t0, t1, t2 and Signature at t0, t1 need to be fetched from remote storage system to local first. Then, File at t0, t1, t2 are reconstructed successively since t1 depends on t0, t2 depends t1.
File at t0 is simply a copy of Delta at t0. File at t1 is resconstruct by File at t0 and Delta at t1, since Delta at t1 contains exsiting chunks in File at t0 and new chunks only exist in File at t1. File at t2 is reconstructed follow same process.
Handle deletion
What if a file is deleted at certain time? For correctly handling file deletion, the deletion needs to be recorded.
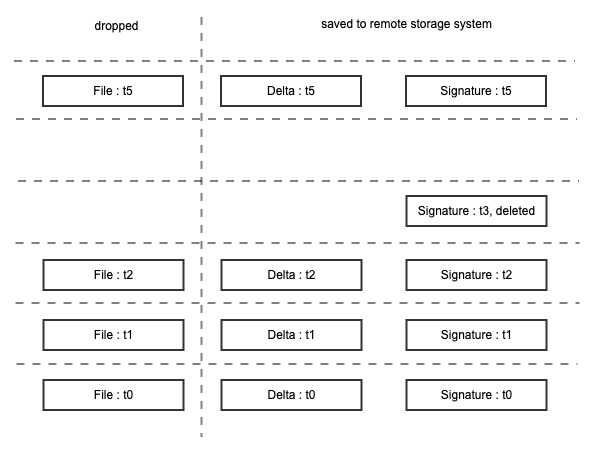
Continue on the former example. At time t3, the file is removed. The deletion at time t3 has to be recorded so that we know the reconstructed File at t2 needs to be removed when files at time t3 are restored. An empty signature file with a suffix deleted can be created to indicate its deletion at time t3. At time t4 (the empty row below t5), we know that the file File is already deleted from the deletion mark of Signature at t3, so that nothing is stored. at time t5, the file File is created again, since there is not a Signature at t4 for it, a full copy for it has to be made - Delta at t5 is same as File at t5.
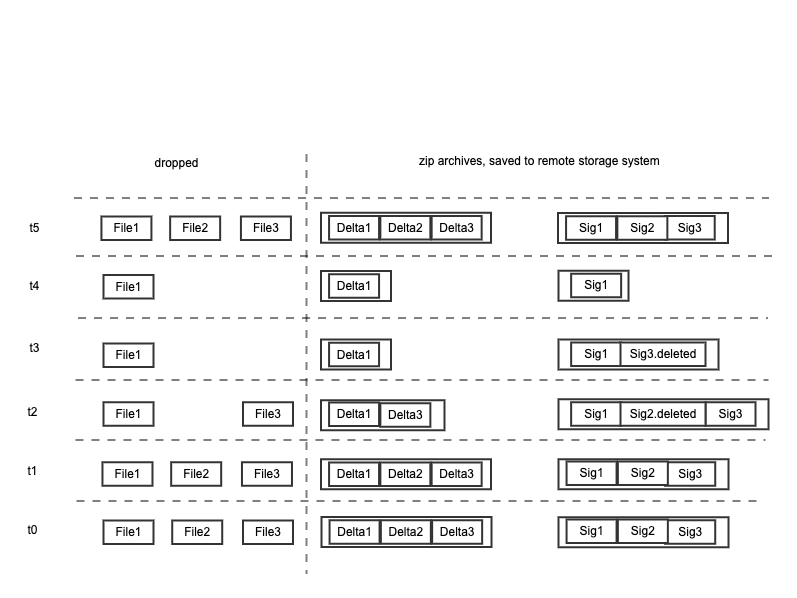
Generate incremental backup for a directory
The incremental backup for a directory can be easily modeled based on the previous single file backup model. All files in a directory need to be treated as a whole. Here goes archiving.
By archiving, not only files in a directory are made a whole, but also the benefits from archiving are gained - reducing the number of small files and further compressing.
At certian time, two zip archives are created: one for saving signature files, another one for saving delta files. The generation process is same as it for single file. As shown below, signature files in the zip archive could have the deletion mark to indicate that certain file is deleted at certain time.
When a directory is backed up, only its last signature zip archive instead of the whole list of signature archives needs to be fetched, since it already contains enough information for generating latest signatures and delta.
Archive format
There are many different archive formats, some provide high compression ratio, while others provide low CPU comsumption, etc. When developing, I have tried zip and tar.gz so here I will only make a breif comparison between these two formats.
A zip archive is a catalog of compressed files. With a gzipped tar, it is a compressed catalog, of files. Thus a zip archive is a randomly accessible list of concatenated compressed items, and a
.tar.gzis an archive that must be fully expanded before the catalog is accessible.
- The caveat of a
zipis that you don’t get compression across files.- The caveat of a
.tar.gzis that you must decompress the whole archive.https://stackoverflow.com/questions/10540935/what-is-the-difference-between-tar-and-zip
When writing code, I encountered two issues with these two formats. First one is that as an optimization file mtime is used to determine whether a file is changed, while zip entry timestamps are recorded only to two 2 second precision. Fortunately, this won’t cause big problem since usually we don’t backup files in such high frequency.
Another issue is that tar.gz does not support streaming, while zip does. Streaming allows data be generated and compressed simultaneously, so that a data processing pipeline can be built on top of it. For example, a writer chain can be built as below, then a simple io.Copy(writer, reader) will trigger the chain to compute the rsync delta, at the same time, compress it and write it to a file on the disk.

Finally, zip was chosen.
Send data to remote
Once delta and signatures generated, it is trivial to send them to remote storage system. To make it extensible, abstract interfaces to do data download and upload can be defined to hide the implementation details of adapting different remote storage systems.
References:
- https://searchdatabackup.techtarget.com/feature/Full-incremental-or-differential-How-to-choose-the-correct-backup-type
- https://www.whymeridian.com/blog/3-data-backup-types-for-business-continuity-full-data-backup-differential-data-backup-and-incremental-data-backup
- https://www.veeam.com/blog/incremental-vs-differential-backups-which-to-choose.html